Formální základy databázové technologie/Datalog
| Zážitky ze zkoušek |
|---|
|
Obsah
Deduktivní databáze
| př. EDB: |
|---|
|
| př. IDB: |
|---|
|
| př. dotazy: |
|---|
|
je db systém, který dokáže provádět dedukce (např. odvodit další fakta) založené na faktech a pravidlech uložených v (deduktivní) db
Deduktivní db se skládá z:
- Extenzionální db (EDB) (uložené tabulky) - tvořené fakty
- fakta - tvrzení, atomické fle obsahující pouze konstanty (statická data, základní informace) - tj. základní literály
- termy - proměnné nebo konstanty
- fakta - tvrzení, atomické fle obsahující pouze konstanty (statická data, základní informace) - tj. základní literály
- Intenzionální db (IDB) (virtuální relace ≈ "pohledy" z SQL) - množina pravidel:
hlava :- tělo- pravidla (v IDB) - jsou Hornovy klausule
L₀ :- L₁,…,Lₙ(návod jak odvodit data, která nejsou explicitně uložena)- literály
Lᵢ- jsou atomické formule (nebo negace a.f.) ve tvaruP(t₁,..,tₖ), kdePje predikátový symbol atᵢje proměnná nebo konstanta -
L₀hlava pravidla,L₁,…,Lₙtělo pravidla - 💡 tvrzení i literály jsou Hornovy klauzule
- literály
- dotazy - výraz jehož výsledkem jsou nalezená a odvozená data
- pravidla (v IDB) - jsou Hornovy klausule
- Integritní omezení (IO)
- tvrzení vymezující korektní DB (na konceptuální a db úrovni)
- př: název_k jednoznačně identifikuje řádky tabulky Kina
- jsou výsledkem snahy kombinovat logické programování s relačními db za účelem vytvořit systém, který podporuje mocný formalismus (s vyjadřovacími schopnostmi logických prog. jazyků) a je stále rychlý a schopný pracovat s velmi rozsáhlými objemy dat.
- mají větší vyjadřovací schopnosti než relační db, ale menší než logické programovací jazyky
| další zdroje |
|---|
|
|
Datalog, 3 sémantiky a jejich ekvivalence.
jazyk používaný v deduktivních db je Datalog - (data)logický program je množinou tvrzení a pravidel
- 💡 vychází z PROLOGu (Datalog je podmnožinou PROLOGu) a využívá vyhodnocovací algoritmy umožňující efektivnější implementaci (operace relační algebry)
| př: nebezpečná pravidla Datalog
|
|---|
|
z přednášky:
z media:Datalog-unsafe_rules.PNG:
(ve všech připadech nekonečnost X splni pravidlo i když je R konečná relace) |
Bezpečné pravidla v Datalogu
- Omezená proměnná x v Datalogu je taková, která se vyskytuje v těle literálu L a pro jehož tělo platí:
- L je dán pravým predikátem, nebo
- pravý predikát - jméno zákl.db relace nebo jméno virtuální relace (prakticky EDB nebo levá strana IDB pravidla)
- L je x = a nebo a = x , kde a je konstanta nebo omezená proměnná
- L je dán pravým predikátem, nebo
Pravidlo je bezpečné pokud jsou ∀proměnné omezené.
Datalog má povolená pouze bezpečná pravidla a dále platí, že v hlavách jsou pouze jména virtuálních relací
- 💡 (ktere nejsou v EDB), tzn odvozováním nevytvářím další základní data
Sémantiku logických programů je možné vybudovat minimálně třemi různými způsoby:
logicko-odvozovací přístup (Proof-Theoretic Approach)
- Metoda: interpretace pravidel jako axiomů použitelných k důkazu, tj. provádíme substituce v těle pravidel a odvozujeme nová tvrzení z hlavy pravidel. V případě DATALOGu tak lze získat právě všechna odvoditelná tvrzení.
logicko-modelový přístup (Model-Theoretic Semantics)
- Predstavme si to jako model v logice (analogicke pro logicko-odvozovaci pristup, kde je to take stejne jako v logice - take se z "axiomu" odvozuji vsechna tvrzeni).
- Metoda: za predikátové symboly dosadíme relace tak, aby na nich byla splněna pravidla.
Příklady z přednášky:
|
Uvažujme logický program LP IDB: P(x) :- Q(x)
Q(x) :- R(x)
tj. Q a P označují virtuální relace.
R(1) Q(1) P(1) Q(2) P(2) M₁ P(3)
|
R(1) Q(1) P(1) M₂
|
💡 při obou sémantikách obdržíme stejný výsledek.
Nevýhody obou přístupů: neefektivní algoritmy v případě, že EDB je dána databázovými relacemi.
| příklad MPB: |
|---|
%EDB: muž(Honza) %IDB: nudný(x) :- ¬zábavný(x), muž(x) zábavný(x) :- ¬nudný(x), muž(x) pak instance databáze
I1: {nudný = {Honza}, zábavný = Ø}
I2: {nudný = Ø, zábavný = {Honza}}
jsou dva MPB (💡 IDB obsahuje neg.cyklus) |
pomocí pevného bodu zobrazení (Fixpoint Semantics)
- Metoda: vyhodnocovací algoritmus + relační db stroj
Nejmenší pevný bod (NPB) rovnice $ R = f(R) $(kde R je bin.schéma relace) je relace $ R^* $ taková, že platí:
- $ R^* = f(R^*) $ (pevný bod)
- $ S^* = f(S^*) ⇒R^*⊆ S^* $ (minimalita)
Minimální pevný bod (MPB) pro program je takový pevný bod R*, že neexistuje žádný další pevný bod, který je vlastní podmnožinou R*.
Z toho plyne:
- ∃ nejmensi pevny bod (NPB), pak je jediným MPB.
- Existuje-li více MPB, pak jsou navzájem neporovnatelné a NPB neexistuje.
| další zdroje |
|---|
|
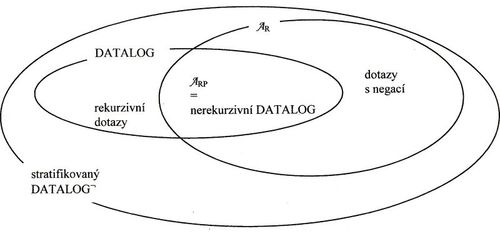
Datalog s negací, stratifikace.
| Zážitky ze zkoušek |
|---|
|
$ A_{RP} \{(), [ ], \cup, \times, rename \} $ (pozitivní RA)
Datalog¬
- Datalog je silnější než $ A_{RP} $, ale existují dotazy v $ A_R $, které v Datalogu nelze vytvořit,
- např.:"kteří překladatelé nepřekládají do angličtiny": PŘEKLÁDÁ[JMÉNO] – (KVALIFIKACE(JAZYK=‘ANGL’)[JMÉNO])
- k vyjádření takovýchto dotazů (obsahujících v relační algebře rozdíl) potřebuje Datalog negaci – je označován Datalog s negací, ovšem způsoby vyhodnocení programů v tomto jazyce obecně nevedou k jednoznačně definovaným virtuálním relacím – proto je identifikována podmnožina Datalogu s negací, která tuto jednoznačnost zajišťuje – tzv. stratifikovaný Datalog (viz dále)
stratifikace
- jedná se o rozvrstvení pravidel do vrstev tak, aby byla zajištěna jednoznačnost vyhodnocování programů
- definujeme pojem definice virtuální relace S, což je množina všech pravidel, kde se S vyskytuje v hlavě
- Program $ P $ je stratifikovatelný, jestliže existuje disjunktní dělení $ P = P_1 ∪ P_2 .... ∪ P_n $ takové, že plati:
- vyskytuje-li se predikátový symbol $ S $ pozitivně (je-li obsažen v pozitivním literálu v těle pravidla) v nějakém pravidle $ P_i $, pak je jeho definice obsažena v $ \bigcup_{1 ≤ k ≤ i}P_k $
- 💡 tj. jeho definice může být ve stejné nebo nižší vrstvě
- vyskytuje-li se predikátový symbol $ S $ negativně (je-li obsažen v negativním literálu v těle pravidla) v nějakém pravidle $ P_i $, pak je jeho definice obsažena v $ \bigcup_{1 ≤ k < i}P_k $
- 💡 tj. jeho definice musí být pouze v nižší vrstvě
- vyskytuje-li se predikátový symbol $ S $ pozitivně (je-li obsažen v pozitivním literálu v těle pravidla) v nějakém pravidle $ P_i $, pak je jeho definice obsažena v $ \bigcup_{1 ≤ k ≤ i}P_k $
- Dělění $ P_1,…, P_n $ se nazývá stratifikace $ P $, každé $ P_i $ je stratum (stratifikace se píše s čárkami pže záleží na pořadí).
- zjišťování, zda je program stratifikovatelný (a nalezení konkrétního dělení) se provádí pomocí závislostních grafů s ohodnocenými hranami (poz/neg podle výskytu pravidla), jestliže se v grafu vyskytuje cyklus s negativní hranou, není program stratifikovatelný
- když je program stratifikovatelný ⇒ má MPB
Příklady z přednášky:
P(x) :- ¬ Q(x) (1) R(1) (2) Q(x) :- Q(x), ¬ R(x) (3)
P(x) :- ¬ Q(x) Q(x) :- ¬ P(x)
A(x,x):-METRO(u,x,y) (1) A(x,y):-A(x,z),METRO(u,z,y) (2) B(x,z):-A(x,y),A(z,y),x!=z (3) O1(y):-A(y,Skalka),y!=Krizikova (4) O2(z):-B(z,Krizikova) (5)
|
%EDB dil(trojkolka, kolo, 3). dil(trojkolka, rám, 1). dil(rám, sedadlo, 1). dil(rám, pedál, 2). dil(kolo, ráfek, 1). dil(kolo, pneumatika, 1). dil(pneumatika, ventilek, 1). dil(pneumatika, duse, 1). %IDB velky(P) :- dil(P,S,Q), Q > 2. maly(P) :- dil(P,S,Q), not velky(P).
|
Tvrzení: Nerekurzivní programy DATALOG¬u vyjadřují právě ty dotazy, které jsou vyjádřitelné v $ A_R $.
předpoklad uzavřeného světa
| (možná už není ve státnicích) |
|---|
* předpoklad uzavřeného světa (CWA) je metapravidlo k odvozování negativní informace
|
| další zdroje |
|---|
| př. rektifikace: |
|---|
|
P(a,x,y) :- R(x,y) P(x,y,x) :- R(y,x) zavedeme u,v,w , substituce: P(u,v,w) :- R(x,y), u = a, v = x, w = y P(u,v,w) :- R(y,x), u = x, v = y, w = x ⇒ P(u,v,w) :- R(v,w), u = a,
|
Algoritmy vyhodnocení dotazů v Datalogu a Datalogu s negací
Obecne pred vyhodnocenim programu se provadi rektifikace - hlavy se stejnym predikatem maji po řadě stejne pojmenovane promenne.
- 💡 Lemma: rektifikace zachovává bezpečnost a je ekvivaletní původnímu výrazu
Nerekurzivní program
| př. algoritmu pro nerekurzivní program: |
|---|
|
C(x,y) :- F(x1,x), F(x2,y), S’(x1,x2)
|
Jedna se o nerekurzivní program, tedy graf je acyklický. Z toho plyne existence topologického uspořádání. Podle tohoto uspořádání zpracovávám virtuální relace.
- pravou stranu převeď na spojení a selekci
- proveď na výsledek projekci
- předchozí dvě pravidla proveď pro všechna pravidla se stejnou hlavou a výsledek sjednoť
💡 tj. v grafu začnu od uzlu ve kterém končí cesty a znej postupuji zpet k dalsim uzlum a je podle nej vyhodnocuji
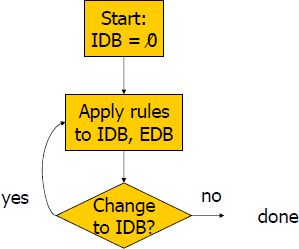
Rekurzivní program
|
|
{kind=link}
Datalog¬
Mejme priklad:
zajimavy(X) :- ¬nudny(X), muz(X). nudny(X) :- ¬zajimavy(X), muz(X).
Extenzionalni tabulka muz obsahuje jeden zaznam 'Honza'. Pak dostavame dva minimalni pevne body (v Datalogu neni zaruceno poradi vykonavani pravidel):
- {zajimavy={Honza}, nudny=Ø}
- {nudny={Honza}, zajimavy=Ø}
Tento problem neexistence nejmensiho pevneho bodu (i neexistence nejmensiho modelu pro logicko-modelovy přístup + neexistence odvozeni pro logicko-odvozovaci přístup) resi stratifikace (viz definice).
Stratifikovaný DATALOG¬
- Předpoklady: pravidla jsou bezpečná, rektifikovaná.
- použije se alg. vyhodnocení Datalogu bez negace, akorát místo případné ¬Q se použije: $ adom^n – Q $
- 💡 $ adom $ - aktuální doména programu, tj. sjednocení všech konstant z EDB a IDB, $ n $ je počet atributů v Q
| další zdroje |
|---|